






.jpg)
.jpg)



Big Data Computations for Analytics: Comparing Distributed Analytical Stores
Dr. Vijay Srinivas Agneeswaran, Director of Technology, SapientNitro | Thursday, 06 April 2017, 05:43 IST
 With a PhD in distributed computing and over 15 years of experience building software for enterprises with recent work on re-engineering machine learning algorithms to work on big-data and in real-time, Storm, Spark, Hadoop, NoSQL databases such as Cassandra, MongoDB, and distributed SQL stores, Vijay currently heads data services teams at SapientNitro as Director of Technology.
With a PhD in distributed computing and over 15 years of experience building software for enterprises with recent work on re-engineering machine learning algorithms to work on big-data and in real-time, Storm, Spark, Hadoop, NoSQL databases such as Cassandra, MongoDB, and distributed SQL stores, Vijay currently heads data services teams at SapientNitro as Director of Technology.
We were dealing with a class of big data analytics from the campaign management media domain that required non-trivial distributed computations. This article summarizes our experience of implementing these computations over common analytical distributed stores and benchmarking of the same.
The nature of computations can be understood by the analogy of a distributed merge tree. Users are identified by unique identifiers called pel ids and are associated with domains such as facebook.com. Domains are grouped into sub-categories which are themselves grouped to form categories. Example of category is social, while a sub-category instance is blog or chat. Similarly, entertainment could be a category with radio or news being sub-categories. The computation involves a merge at each level of the tree above the leaf – it should be noted that merge may involve string sort and removal of duplicates. The overall computation involves a merge all the way up to the root of the tree and a count of records at each node divided by the overall count giving reachability of a node in domain parlance.
We have implemented the same computations on top of state-of-art analytical stores such as Apache HAWQ and Druid. Druid is emerging as an important analytical store that helps in performing ad-hoc queries on large data sets, while HAWQ is a distributed SQL engine over the Hadoop Distributed File System (HDFS).
Apache HAWQ and Druid Custom Achitectures
It must be noted that while HAWQ does not mandate minimum number of nodes for a cluster, Druid recommends at least 4 (one for Broker, Coordinator, two data/historical nodes and one node for Zookeeper). Our HAWQ architecture is very specialized and is given in figure 1.
We formed three HAWQ clusters, each cluster having a partition of the data and each cluster partitioning the data within itself using a multi-dimensional partitioning. While it could be questioned as to why we did not have 3 Druid clusters, it must be kept in mind that Druid requires different types of nodes within a cluster such as the Broker, Coordinator, Zookeeper and historical nodes.
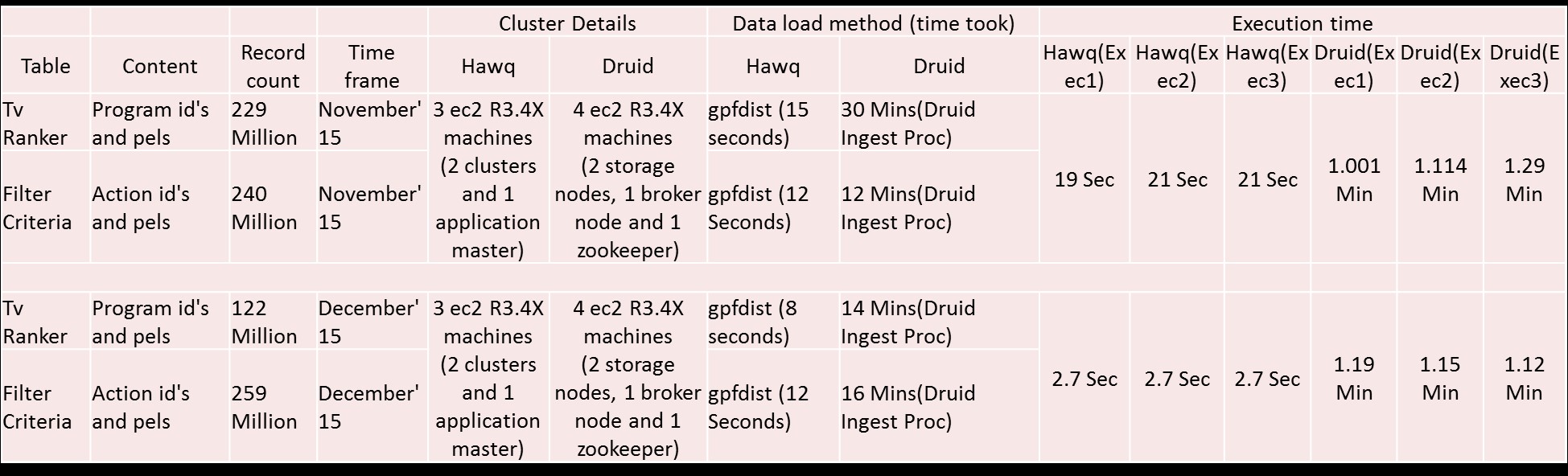
The table one captures one set of performance benchmarks comparing HAWQ and Druid. A few definitions to make the table clearer are given below: pel_ids are unique ids generated for each user in the audience. All the demographic attributes, actions & behaviors performed by the users are then linked to this id. Action_ids represent the set of high value actions performed by the users. This includes activities such as watching a program, visiting a website etc. Program_id refers to the unique id assigned to a program/series. The above mentioned computations took about 20 seconds on a HAWQ AWS 3-node cluster, while it took about a minute on a Druid AWS 4-node cluster.
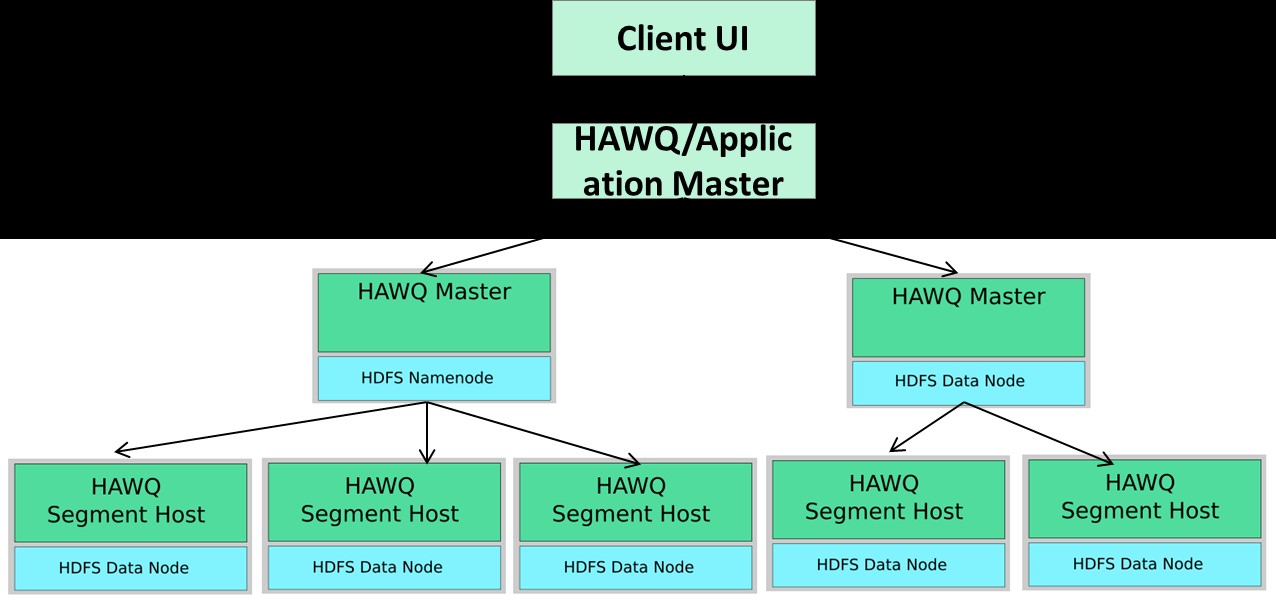
Figure 1: HAWQ Architecture for Distributed Computations
Table 1: Performance Analysis of Apache HAWQ and Druid
While the table 1 looks at queries with respect to specific queries on certain action ids and program ids, table two captures another facet of this performance analysis where we pass through a whole set of possible program ids (which could be about 22,000). This implies the data store has to loop through the list of program ids and run queries against each quickly. In this case, Druid could not even complete and was taking indeterminately time to respond, while HAWQ was able to respond within a minute and half.
Table 2: All program IDs - Long Running Query

Conclusion
All in all, HAWQ due to its distributed query engine and optimized query planning and execution, is able to perform these computations much quicker. Another reason is the multi-dimensional partitioning available on HAWQ –this was one of the main reasons for choosing HAWQ as opposed to other distributed SQL engines such as Impala, Spark SQL. While Druid is good at scalar aggregations, we needed String compare and de-duplicate based aggregations (for merge) and these were not efficient enough on Druid. We are planning to extend the comparison to include certain in-memory distributed SQL stores such as Memcache and GPU databases such as Kinetica. For more details, please attend my Strata talk in London.
https://conferences.oreilly.com/strata/strata-eu/public/schedule/detail/57397
CIO Viewpoint
Accept Data as an Entity on Balance sheet
By Akshey Gupta, Chief Data Officer, Bandhan Bank

Technology Forecast And Concern In 2020
By Anil Kumar Ranjan, Head IT, Macawber Beekay Private Limited

Data Analytics For Enhanced Productivity And...
By Krishnakumar Madhavan, Head IT, KLA
CXO Insights

Regulatory Implications and Data Protection:...
By Richa Singh

Data-Driven Predictive Technologies
By Pankaj Parimal, Head of Launch & Change Management, Hella Automotive Mexico, S.A. de C.V., Mexico, North America.

5 Mantras That Can Drive Organizations Towards...